From hypothesis to experiment
从假设到实验 A layered schema from computational hypotheses to experimental validation
Function to Procedure schema · Part 1
随着越来越多的蛋白质被计算方法自动标注,社区中仍然存在一个明显的 gap:我们生成蛋白质功能假设的速度越来越快,但验证这些功能假设的速度仍然非常慢。
在这里,我们尝试对“从一个 hypothesis 开始,到最后完成实验验证”的过程进行一次系统性的归纳和梳理。
需要注意的是,在本文中,我们所说的 hypothesis 指的是一段描述蛋白质功能、性质或作用机制的自由文本。它可以来自传统的序列/结构比对方法,也可以来自机器学习模型、深度学习模型,或者最近的多模态大模型。
从 hypothesis 到最终实验验证,我们可以把整个过程大致分成三个层面:
- 概念层
- hypothesis
- claims
- 中间层
- sub-claims
- assays
- 物理层
- procedures / transport
- resources
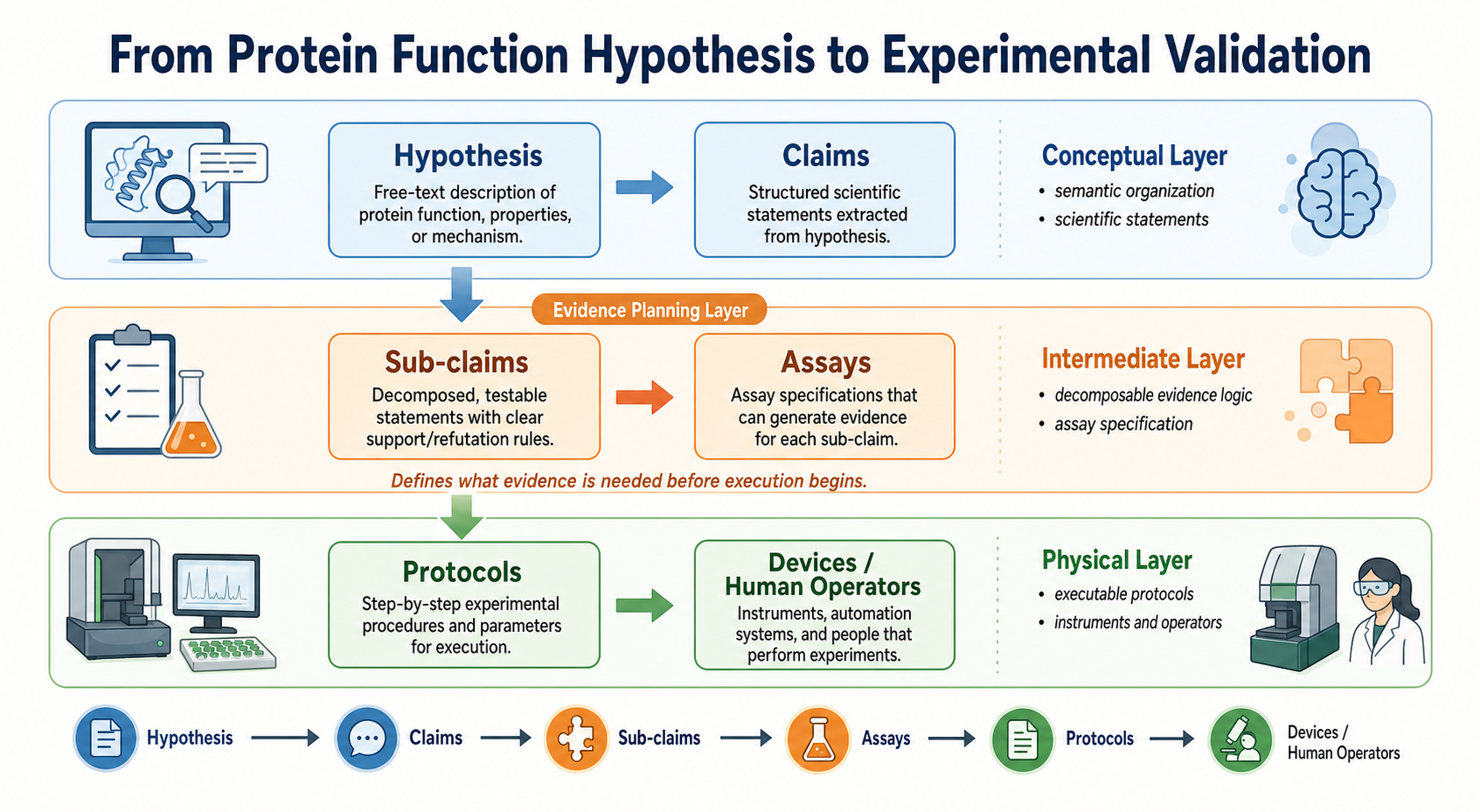
接下来,我们分层进行阐述。
概念层
Hypothesis
对于一个蛋白质来说,人类很难像读懂中文或者英语那样直接读懂蛋白质序列中的“语义”。因此,我们发明了各种计算工具来对蛋白质的功能、性质和作用机制进行标注。
传统的蛋白质功能标注手段主要可以分成两类:相似度搜索和直接预测。
相似度搜索指的是:给定一条蛋白质序列,基于某种相似性比对工具,例如 BLASTP、Foldseek、ESM embedding 或 ProTrek embedding,计算该序列与某个参考数据库中已有蛋白质的相似性,并进行排序。随后,我们将相似蛋白质,或者相似蛋白质集合的已知功能,作为这条查询序列功能的一种候选解释。
直接预测指的是:不给定显式的参考数据库,只给定一条蛋白质序列,基于某种机器学习或深度学习模型的输出结果来预测该蛋白质的功能或性质。例如,模型可以直接预测一个蛋白质的最适 pH、\(K_{cat}\)、EC 号、亚细胞定位、是否具有某种结合能力,或者是否属于某个功能类别。
Note
当然,所谓“直接预测”本质上也是基于训练数据学习得到的统计规律。从更广义的角度看,它也可以被认为是某种隐式的相似性搜索:模型在参数空间中学习了已知蛋白质及其功能之间的对应关系,并将这种关系推广到新的蛋白质上。
最近,也出现了一些蛋白质多模态模型。这类模型可以接受蛋白质序列、结构、文本问题,甚至其他上下文信息,并直接输出自然语言形式的回答。例如,用户可以向模型询问:“这个蛋白质可能参与什么生物过程?”或者“这个蛋白质是否可能具有激酶活性?”,模型则直接生成一段自由文本作为回答。
为了在形式上统一这些不同来源的标注,我们可以将所有关于蛋白质的功能描述都统一表示为自由文本。无论它原本是一个数据库检索结果、一个数值预测结果、一个分类标签,还是一段大模型生成的自然语言解释,都可以被转写成一段 hypothesis。
例如:
| 来源类型 | 原始输出形式 | 统一后的 hypothesis 示例 |
|---|---|---|
| 序列相似度搜索 | Top hit 为一个已知的 beta-lactamase | 该蛋白质可能具有 beta-lactamase 活性,能够水解 beta-lactam 类抗生素。 |
| 结构相似度搜索 | Foldseek 检索结果显示其结构与已知 serine protease 高度相似 | 该蛋白质可能是一种 serine protease,并通过催化三联体参与肽键水解。 |
| embedding 检索 | 在 ESM embedding 空间中接近一组 DNA-binding proteins | 该蛋白质可能具有 DNA 结合能力,并可能参与转录调控或基因表达调节。 |
| 酶功能预测模型 | EC number = 2.7.11.1 | 该蛋白质可能是一种蛋白激酶,能够将磷酸基团转移到底物蛋白的氨基酸残基上。 |
| 性质预测模型 | optimal pH = 7.5 | 该蛋白质的最适反应 pH 可能接近 7.5。 |
| 动力学参数预测模型 | \(K_{cat} = 12.3\,s^{-1}\) | 在给定底物和实验条件下,该蛋白质催化反应的 \(K_{cat}\) 可能约为 \(12.3\,s^{-1}\)。 |
| 亚细胞定位预测模型 | mitochondrial protein | 该蛋白质可能定位在线粒体中,并在该细胞器内发挥功能。 |
| 多模态蛋白质大模型 | 自然语言回答 | 该蛋白质可能作为某种受体参与信号转导,并在细胞生长、分化或代谢调控中发挥作用。 |
在本文中,我们将这些由计算方法生成的、关于蛋白质功能或性质的自由文本描述,统一称为 hypothesis。
Claims
在概念层中,hypothesis 通常是一段自由文本,而 claim 则是从这段自由文本中抽取出来的、更加明确的科学命题。
换句话说,claim 是 hypothesis 中可以被进一步讨论、判断或验证的最小语义单元之一。
这里需要特别强调一点:在 claim 这一层,我们并不关心“应该用什么实验去验证它”。也就是说,我们不会在这一步把 claim 绑定到具体 assay、procedure 或 device 上。claim 层仍然是一个纯概念层,它的目标是把自然语言中的功能描述整理成结构化、可比较、可推理的科学命题。
一般来说,一个好的 claim 至少应该包含以下几个方面的信息:
| 字段 | 含义 |
|---|---|
| 原文片段 | claim 在 hypothesis 中对应的原始文本片段。 |
| 重新叙述的 statement | 将原文片段改写成一个更加清晰、独立、可判断真假的科学命题。 |
| testability | 这个 statement 在概念上是否具有可验证性。可以分为 testable、partially_testable、not_directly_testable、needs_clarification。 |
| confidence | 我们对“这个 claim 是否被原文支持、抽取是否合理”的置信度,而不是对这个 claim 生物学真假的置信度。 |
| reasons or suggestions | 为什么这样判断;如果 claim 不够清晰,应该如何在概念层面进一步改写或拆分。 |
这里的 testability 可以粗略理解为:
| testability 类型 | 含义 |
|---|---|
testable | 这个 statement 已经足够明确,原则上可以在后续层级中被转化成验证任务。 |
partially_testable | statement 中有一部分是明确的,但它可能包含多个子命题,或者缺少部分条件。 |
needs_clarification | statement 的方向是有意义的,但目前缺少关键概念、对象、条件或关系,需要进一步澄清。 |
not_directly_testable | statement 更像是总结性、修辞性、重要性判断或背景描述,不能直接作为一个科学命题来验证。 |
需要注意的是,这里的 testability 仍然只是在概念层进行判断。我们只是在问:
这个 statement 是否已经像一个可以被判断真假的科学命题?
而不是在问:
应该用什么实验方法来验证它?
后者属于后面的中间层和物理层。
对于一些传统方法得到的标注来说,它们本身可能已经非常接近一个 claim,因此不一定需要复杂的拆解过程。例如,一个 EC 号、一个最适 pH 值、一个亚细胞定位标签,通常都可以比较直接地转化成一个候选科学命题。
例如:
| 原始 hypothesis / 标注 | 原文片段 | 重新叙述的 statement | testability | confidence | reasons or suggestions |
|---|---|---|---|---|---|
| 该蛋白质的 EC 号可能是 3.1.1.1。 | EC 号可能是 3.1.1.1 | 该蛋白质可能具有 carboxylesterase 活性。 | testable | high | EC 号本身已经对应一个相对明确的酶功能类别,因此可以比较直接地转写成一个功能 claim。 |
| 该蛋白质的最适 pH 可能是 7.5。 | 最适 pH 可能是 7.5 | 该蛋白质的功能活性可能在 pH 7.5 附近达到最高。 | partially_testable | high | “最适 pH”是一个明确性质,但仍然隐含了“针对什么活性、什么底物或什么功能 readout”的问题,因此可以作为 claim,但后续可能需要进一步限定条件。 |
| 该蛋白质可能定位在线粒体。 | 定位在线粒体 | 该蛋白质在细胞内主要定位于线粒体。 | testable | high | 亚细胞定位是一个相对明确的性质,statement 中的对象和位置都比较清楚。 |
| 该蛋白质可能结合 ATP。 | 结合 ATP | 该蛋白质能够与 ATP 发生特异性结合。 | testable | high | “蛋白质—ATP 结合”是一个明确的分子关系。但如果需要更严格的 statement,可以进一步补充结合强度、结合位点或生理条件。 |
| 该蛋白质可能是一种转录因子。 | 是一种转录因子 | 该蛋白质可能具有转录因子相关功能。 | partially_testable | medium | “转录因子”本身可能包含多个子含义,例如 DNA 结合、转录激活或转录抑制。因此这个 claim 可以继续拆成更具体的子命题。 |
这些例子中,hypothesis 和 claim 之间的距离比较短。换句话说,原始标注本身已经比较结构化,因此我们只需要做轻量级的语义转写,就可以得到一个相对明确的 claim。
但是,对于更加复杂的自由文本来说,从 hypothesis 中拆解出一个个可判断真假的 claims 就变得非常重要。
下面是 Evolla 的一段输出:
This protein functions as a receptor for insulin-like growth factors (IGFs), which are critical for regulating cell growth and metabolism. It is a member of the insulin receptor family and plays a pivotal role in mediating the effects of IGFs on various tissues and cells. The protein is a subunit of a tetramer that includes two alpha and two beta subunits, and it interacts with several other proteins, including insulin-like growth factor-binding proteins and various regulatory proteins.
The primary function of this protein involves the transmembrane signaling process. When IGFs bind to this receptor, it initiates a cascade of events that leads to the phosphorylation of tyrosine residues, which is a key step in activating downstream signaling pathways. These pathways regulate cell growth, differentiation, and survival.
The protein's role is also linked to the regulation of IGF receptor signaling pathways. It interacts with other proteins such as insulin-like growth factor-binding proteins, which can modulate the affinity of the receptor for IGFs, and with regulatory proteins like SOCS1, which can inhibit the receptor's activity.
Additionally, the protein's function is influenced by post-translational modifications, such as autophosphorylation, which is essential for its activation. The presence of different isoforms, such as the long and short forms, suggests that these variants may have distinct roles in different tissues and during various developmental stages.
In summary, this protein acts as a critical component in the IGF signaling pathway, facilitating the binding of IGFs and initiating a series of events that regulate cell growth and metabolism. Its interactions with other proteins and its role in post-translational modifications underscore its complexity and importance in cellular processes.
这段文本看起来很完整,也很像一段标准的蛋白质功能解释。但是,如果我们想要把它转化成后续可以处理的验证任务,就必须先在概念层进行 claim extraction。
这一步的核心问题不是“应该做什么实验”,而是:
这段 hypothesis 中到底包含了哪些可以被判断真假的科学命题?
| 原文片段 | 重新叙述的 statement | testability | confidence | reasons or suggestions |
|---|---|---|---|---|
| This protein functions as a receptor for insulin-like growth factors (IGFs) | 该蛋白质可能作为 insulin-like growth factors (IGFs) 的受体。 | testable | high | 原文明确声称该蛋白质是 IGFs 的 receptor。这个 statement 的对象和功能关系都比较清楚。后续如果需要更精确,可以进一步区分是 IGF1、IGF2,还是其他 IGF-like ligand。 |
| It is a member of the insulin receptor family | 该蛋白质可能属于 insulin receptor family。 | testable | high | 原文直接给出了家族归属。该 statement 比较清晰,属于分类型 claim。 |
| … | … | … | … | … |
从这个例子可以看到,复杂 hypothesis 中通常混合了多种不同类型的claims。
这些 claim 并不处在同一个粒度上。有些 claim 已经比较明确,例如“该蛋白质属于 insulin receptor family”;有些 claim 则比较宽泛,例如“该蛋白质参与 transmembrane signaling”;还有一些 claim 实际上混合了多个子命题,例如“该蛋白质启动下游事件并调控 cell growth and metabolism”。
因此,从 hypothesis 中抽取 claims 的关键,并不是简单地把长文本切成短句,而是要把自然语言中的功能描述转化成可以被判断真假的科学命题。
与此同时,hypothesis 中也常常包含一些不适合作为直接 claim 的内容。例如:
| 原文片段 | 重新叙述的 statement | testability | confidence | reasons or suggestions |
|---|---|---|---|---|
| plays a pivotal role in mediating the effects of IGFs | 该蛋白质在介导 IGFs 作用时具有关键作用。 | not_directly_testable | high | “pivotal role” 是重要性判断,不是一个具体机制或关系。建议改写为更具体的依赖关系,例如该蛋白质是否是某个 ligand response 所必需的。 |
| critical for regulating cell growth and metabolism | 该蛋白质对 cell growth 和 metabolism 的调控至关重要。 | not_directly_testable | medium | “critical” 是强重要性判断,而且 cell growth 和 metabolism 都是很宽泛的表型类别。建议拆分为更具体的 phenotype-level claims。 |
| … | … | … | … | … |
因此,一个好的 claim extraction 过程,应该尽量完成以下几件事:
保留原文依据
每个 claim 都应该能追溯回 hypothesis 中的具体文本片段。改写成独立 statement
claim 不应该只是一个名词短语,而应该是一个完整的科学命题。避免在 claim 层绑定实验方法
在这一层,我们只判断 statement 是否清楚、是否有可验证性,而不决定具体用什么 assay 或 procedure。区分不同 testability 类型
有些 statement 已经可以直接作为 claim;有些需要拆分;有些需要补充条件;有些只是总结性语言,应当过滤掉。明确 confidence 的含义
这里的 confidence 指的是“这个 claim 是否被原文支持、抽取是否合理”,而不是“这个 claim 在生物学上是否为真”。给出 reasons or suggestions
如果一个 claim 不够清楚,不应该直接丢弃,而应该说明它为什么不清楚,以及在概念层面应该如何进一步改写。
因此,claim 层的核心任务可以总结为:
将自由文本 hypothesis 中的功能描述,转化为一组有原文依据、语义清晰、粒度适当、可进一步处理的候选科学命题。
只有完成这一步之后,我们才能进入下一层:将 claims 进一步拆解成 sub-claims,并在更靠近实验设计的层面讨论 assays。