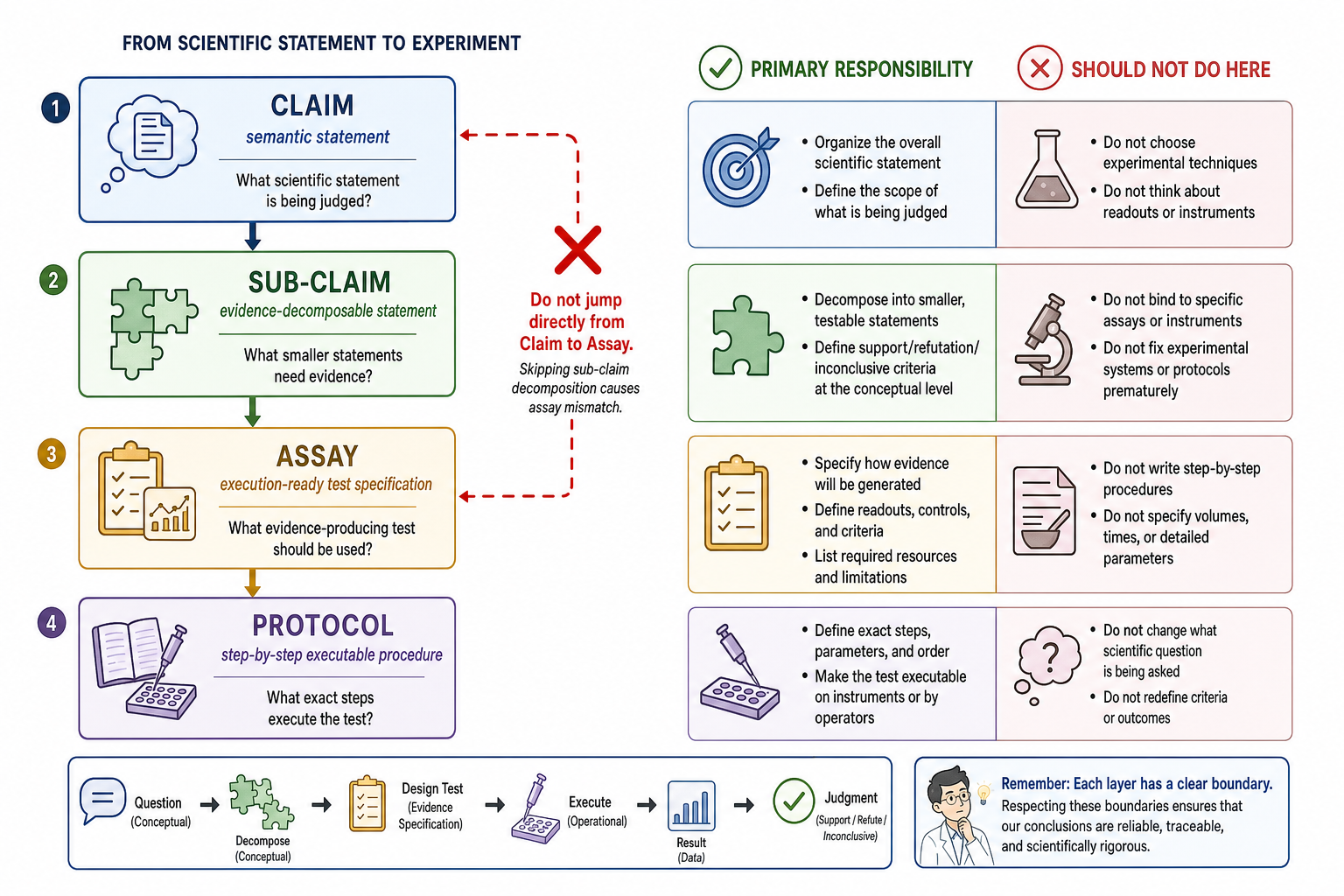
From hypothesis to experiment
中间层:Sub-claims 与 Assay The middle layer: from claims to sub-claims and assays
Function to Procedure schema · Part 2
随着越来越多的蛋白质被计算方法自动标注,社区中仍然存在一个明显的 gap:我们生成蛋白质功能假设的速度越来越快,但验证这些功能假设的速度仍然非常慢。
在这里,我们尝试对“从一个 hypothesis 开始,到最后完成实验验证”的过程进行一次系统性的归纳和梳理。
需要注意的是,在本文中,我们所说的 hypothesis 指的是一段描述蛋白质功能、性质或作用机制的自由文本。它可以来自传统的序列/结构比对方法,也可以来自机器学习模型、深度学习模型,或者最近的多模态大模型。
从 hypothesis 到最终实验验证,我们可以把整个过程大致分成三个层面:
- 概念层
- hypothesis
- claims
- 中间层
- sub-claims
- assays
- 物理层
- procedures / transport
- resources
接下来,我们分层进行阐述。
中间层
中间层是连接概念层和物理层的层次。
概念层处理的是 hypothesis、claim 这类自然语言或半结构化的科学命题;物理层处理的是 procedure、instrument、sample、operator、device 这类可以被实验室系统执行的对象。中间层的作用,就是把一个上游 claim 转换成物理层能够理解、执行和回填结果的形式。
换句话说,中间层回答的问题不是:
这个 hypothesis 听起来是否合理?
也不是:
实验人员应该一步一步怎么操作?
而是:
为了判断这个 claim 是否成立,我们需要拆成哪些更小的、可实验判定的 sub-claims? 每个 sub-claim 应该由什么类型的 assay 来产生证据? 什么样的实验结果支持它,什么样的实验结果拒绝它,什么样的结果只能说明证据不足?
因此,中间层主要包含两个核心对象:
- Sub-claim
- Assay
Sub-claim 和 Assay 是一体两面的关系。
- Sub-claim 更接近概念层。它的任务是把上游 claim 拆解成若干个更小、更明确、更可实验判定的命题。
- Assay 更接近物理层。它的任务是把某个 sub-claim 绑定到一套可以产生证据的实验设计中,包括 readouts、controls、replicates、support criteria、refutation criteria 等。
可以简单理解为:
| 层次 | 主要问题 | 输出对象 |
|---|---|---|
| Claim | 我们想判断的科学命题是什么? | 一个相对完整的 statement |
| Sub-claim | 为了判断这个 claim,需要拆成哪些更小的命题? | 可实验判定的局部 statement |
| Assay | 用什么实验计划产生证据? | readouts、controls、criteria、resources |
| Procedure | 实验具体怎么做? | 可执行步骤、仪器参数、操作流程 |
需要注意的是,凭空生成 assay 是不可靠的。一个 sub-claim 是否可以被某类 assay 支持,应该尽量依赖已有的人类知识库、标准实验范式、文献、数据库或实验室内部 SOP,而不是只由语言模型直接想象出来。
因此,从 sub-claim 到 assay 的过程更合理的方式是:
- Retrieve:从已有知识库、文献、procedure database 或实验室 SOP 中检索相关 assay。
- Rank:根据 sub-claim 的对象、关系、条件、readout 需求,对候选 assay 进行排序。
- Adapt:如果已有 assay 不能完全匹配当前 sub-claim,则以已有 assay 作为模板进行微调。
- Justify:记录为什么选择这个 assay,它对应哪个 sub-claim,哪些地方是从已有模板修改而来。
- Validate:检查 assay 的 readouts 是否真的能够支持或拒绝对应的 sub-claim。
最后,在中间层结束之前,需要安排一次内容检查。因为中间层的输出会直接影响物理层的实验执行,所以必须确保这里的逻辑拆解、assay 选择和判定标准都是一致的。否则,上游 claim 的表达错误、sub-claim 的拆解错误,或者 assay 与 sub-claim 的错配,都会污染最后的实验结果。
Sub-claims
Sub-claim 是从 claim 中拆解出来的、更小的、可实验判定的科学命题。
一个 claim 往往太大、太抽象,不能直接进入实验层。例如:
This protein functions as a receptor for insulin-like growth factors (IGFs).
这个 claim 看起来很清楚,但如果要实验验证,就会立刻遇到很多问题:
- 这里的 IGFs 指的是 IGF-1、IGF-2,还是更广义的 IGF-like ligands?
- “functions as a receptor” 是只要求 ligand binding,还是还要求 downstream signaling?
- 这个 receptor function 是在体外体系中判断,还是在细胞环境中判断?
- 如果这个蛋白能结合 IGF-1 但不能结合 IGF-2,算不算支持原始 claim?
- 如果它能结合 IGF ligand,但不能激活下游 signaling,算不算 receptor?
这些问题说明,claim 需要被拆成更明确的 sub-claims。
Sub-claim 的目标不是把一句话机械地切成更短的句子,而是要把 claim 拆成可以分别获得证据、分别判断状态、并最终组合回原始 claim 的局部命题。
一个好的 sub-claim 通常应该满足以下条件:
对象明确 例如,不只是说 “binds IGFs”,而是明确为 “binds IGF-1” 或 “binds IGF-2”。
关系明确 例如,是 binding、activation、inhibition、localization,还是 pathway regulation。
判定方向明确 应该能说清楚什么结果支持它,什么结果拒绝它,什么结果只能算 inconclusive。
能够映射到 assay Sub-claim 本身仍然是概念层命题,但它必须足够具体,以便后续可以找到对应的 assay。
每一个 sub-claim 至少需要包含以下信息:
| 字段 | 含义 |
|---|---|
sub_claim_id | sub-claim 的唯一 ID。 |
parent_claim_id | 它来自哪个上游 claim。 |
statement | sub-claim 的自然语言陈述。 |
support_criteria | 什么样的证据在概念上支持这个 sub-claim。 |
refutation_criteria | 什么样的证据在概念上拒绝这个 sub-claim。 |
inconclusive_criteria | 什么情况不能支持也不能拒绝,只能认为证据不足。 |
safety_notes | 与这个 sub-claim 相关的安全、伦理或材料风险提示。 |
这里需要区分三种状态:
| 状态 | 含义 |
|---|---|
supported | 当前证据支持 sub-claim。 |
refuted | 当前证据拒绝 sub-claim。 |
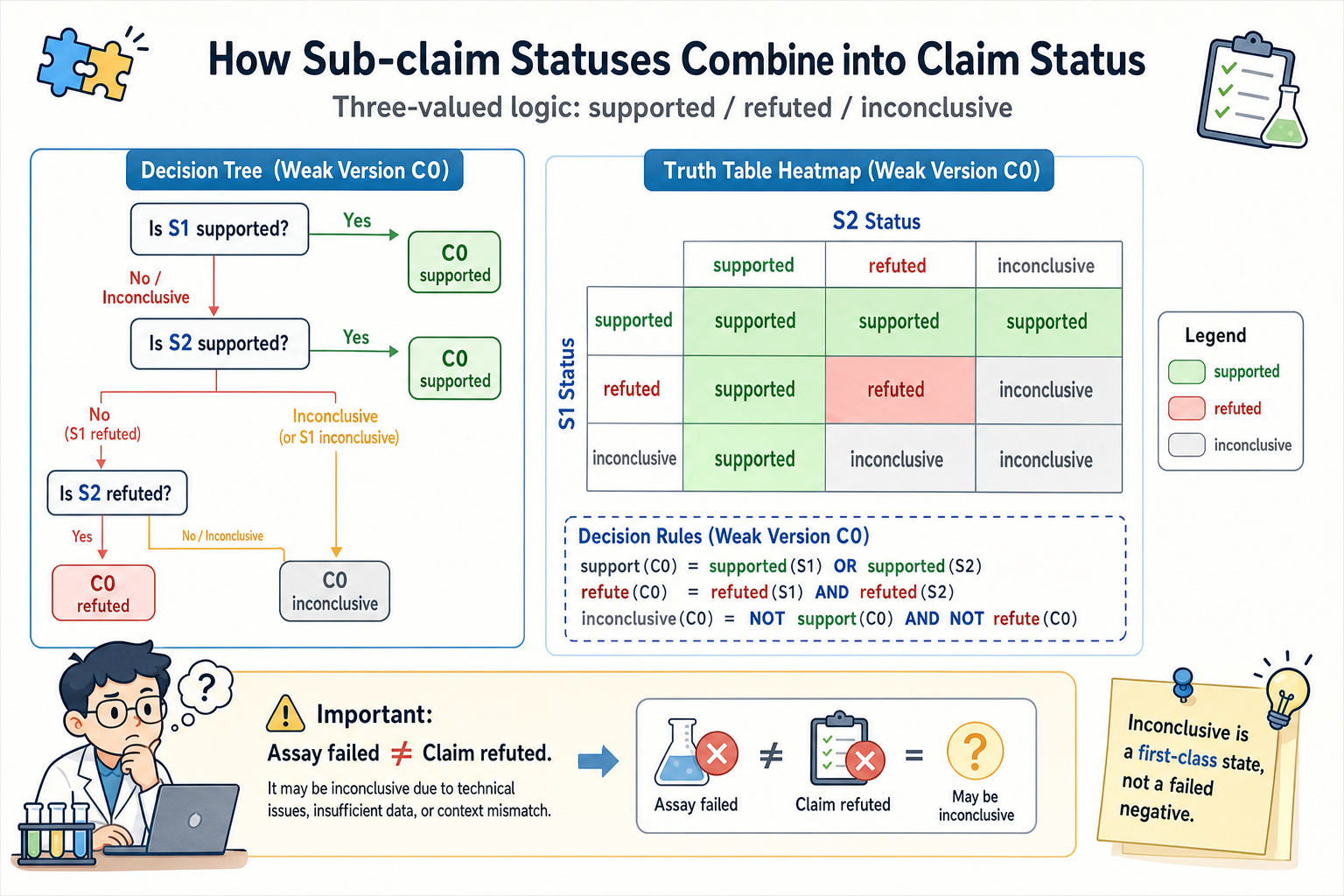
inconclusive | 当前证据不足、实验失败、上下文不匹配,或者结果互相矛盾。 |
也就是说,sub-claim 的结果不应该被强行二分成“支持”和“拒绝”。在真实实验中,很多结果既不能支持也不能拒绝,只能说明当前 assay、样本、条件或 readout 不足以做出判断。
例子:将 IGF receptor claim 拆解为 sub-claims
假设上游 claim 是:
| claim id | statement |
|---|---|
C0 | This protein functions as a receptor for insulin-like growth factors (IGFs). |
如果我们暂时采用一个相对弱的定义:
只要该蛋白能特异性结合至少一种 IGF ligand,就认为它在 ligand-binding 意义上支持 IGF receptor claim。
那么可以拆成两个 sub-claims:
| sub-claim id | statement |
|---|---|
S1 | This protein specifically binds IGF-1. |
S2 | This protein specifically binds IGF-2. |
这时,支持或拒绝上游 claim 的规则可以写成:
support(C0) = supported(S1) OR supported(S2)
refute(C0) = refuted(S1) AND refuted(S2)
inconclusive(C0) = NOT support(C0) AND NOT refute(C0)
也就是说:
| S1: binds IGF-1 | S2: binds IGF-2 | C0 判断 |
|---|---|---|
| supported | supported | support C0 |
| supported | refuted | support C0 |
| refuted | supported | support C0 |
| refuted | refuted | refute C0 |
| inconclusive | supported | support C0 |
| supported | inconclusive | support C0 |
| inconclusive | refuted | inconclusive C0 |
| refuted | inconclusive | inconclusive C0 |
| inconclusive | inconclusive | inconclusive C0 |
但是,如果我们采用一个更强的定义:
一个 functional IGF receptor 不仅要能结合 IGF ligand,还需要在相关 context 中触发 receptor activation 或 downstream signaling。
那么上面的拆解就不够了。我们还需要增加一个 sub-claim:
| sub-claim id | statement |
|---|---|
S3 | Binding of IGF-1 or IGF-2 to this protein leads to receptor activation or downstream signaling in a relevant biological context. |
这时,强版本 claim 可以写成:
support(C0_strong) = (supported(S1) OR supported(S2)) AND supported(S3)
refute(C0_strong) = (refuted(S1) AND refuted(S2)) OR refuted(S3)
inconclusive(C0_strong) = NOT support(C0_strong) AND NOT refute(C0_strong)
这说明,同一个原始 claim 可以有不同强度的形式化版本。中间层需要明确当前使用的是哪一种定义,否则后面的 assay 设计会变得混乱。
Sub-claim 形式化表示
对于上面的例子,可以把 sub-claims 写成下面的结构:
| sub_claim_id | parent_claim_id | statement | support_criteria | refutation_criteria | inconclusive_criteria | safety_notes |
|---|---|---|---|---|---|---|
S1 | C0 | This protein specifically binds IGF-1. | 存在可重复的、特异性的 IGF-1 binding evidence,并且能够排除明显的 nonspecific binding。 | 在蛋白质量、ligand 质量和检测系统均合格的情况下,反复未观察到 IGF-1 specific binding。 | 蛋白不稳定、ligand 失活、背景过高、positive control 失败、不同实验结果矛盾。 | 如果使用细胞系统,需要考虑细胞来源、培养条件和生物安全等级。 |
S2 | C0 | This protein specifically binds IGF-2. | 存在可重复的、特异性的 IGF-2 binding evidence,并且能够排除明显的 nonspecific binding。 | 在蛋白质量、ligand 质量和检测系统均合格的情况下,反复未观察到 IGF-2 specific binding。 | 蛋白不稳定、ligand 失活、背景过高、positive control 失败、不同实验结果矛盾。 | 如果使用细胞系统,需要考虑细胞来源、培养条件和生物安全等级。 |
S3 | C0 | IGF binding to this protein leads to receptor activation or downstream signaling. | IGF stimulation 后出现与该蛋白相关的 activation 或 downstream signaling evidence。 | 在系统有效、表达正常、ligand 有效的情况下,IGF stimulation 不引起相关 activation 或 downstream signaling。 | 细胞模型不表达必要 cofactor、readout 不敏感、内源性 receptor 干扰、activation marker 不明确。 | 细胞实验可能涉及人源细胞、转染或刺激处理,需要根据材料进行安全审查。 |
这个例子展示了 sub-claim 的作用:它不是直接给出实验步骤,而是把一个较大的 claim 拆成可以被 assay 分别判断的小命题,并且为每个小命题定义清楚支持、拒绝和不确定的条件。
Assay
Assay 可以定义为:
“a planned process with the objective to produce information about the material entity that is the evaluant, by physically examining it or its proxies”
也就是说,assay 是一个有计划的过程,它的目标是通过对评估对象 (evaluant) 本身或其替代物 (proxies) 进行物理检查,从而产生关于该实体的信息。引用
把这个定义拆开,一个 assay 至少包含五个关键点:
它是一个有计划的过程 (a planned process)
Assay 不是随便观察一下,而是事先设计好的、有明确步骤的检测过程,可以理解为一个有向无环图 (Directed Acyclic Graph, DAG):从样品准备到信号读取,每一步都有确定的先后顺序和操作规范。
例如,随手拿起一管蛋白对着灯看一下,不算 assay;按照一个明确方案依次加试剂、孵育、测定吸光度,则可以算 assay。它的目标是产生信息 (the objective to produce information)
Assay 的直接目标是获得数据或判断,也就是说它必须有一个 output——即 readout,而不是以获得产物为目的。
例如,纯化蛋白的主要目标是得到蛋白样品,因此它本身通常不是 assay;用 BCA 法测定蛋白浓度的目标是获得一个浓度数值(readout),因此它是 assay。它有一个被评估的物质实体 (the material entity that is the evaluant)
Assay 必须有一个明确的 input——即 evaluant,也就是你要获取信息的那个物质实体。没有 evaluant 的过程不构成 assay。
例如,在测定蛋白浓度的 assay 中,evaluant 是那管蛋白样品;在药物筛选 assay 中,evaluant 是候选化合物。它通过物理手段进行检查 (physically examining)
Assay 要求对物质实体进行物理上的检测,而不能是纯粹的计算、推理、文献检索或 in silico 模拟。
例如,测量吸光度、荧光信号、质谱信号、SPR 结合响应、细胞成像信号,都属于物理检查;而用 AlphaFold 预测结构、用分子对接打分,则不属于 assay 中”physically examining”的范畴。它可以检查对象本身,也可以检查 proxy (the evaluant or its proxies)
有些性质不能直接观察,因此 assay 允许通过与目标性质具有相关性的 proxy 来间接获取信息。
例如,酶活性本身不是一个可以直接”看见”的东西,但底物消耗速率、产物生成量、吸光度变化或荧光变化都可以作为 enzyme activity 的 proxy;再比如,蛋白-蛋白相互作用本身不可见,但 FRET 信号变化可以作为它的 proxy。
因此,assay 的作用不是重复 sub-claim,而是把 sub-claim 转换成一套有明确 input (evaluant)、明确 output (readout)、通过物理手段执行的实验设计。
Assay 和 Sub-claim 的区别
Sub-claim 和 Assay 是严格的一一对应关系:每一个 sub-claim 都必须对应恰好一个 assay,每一个 assay 也只服务于恰好一个 sub-claim。二者的 criteria 在概念上一致,只是分工不同。
| 对象 | criteria 的含义 |
|---|---|
| Sub-claim criteria | 概念层面的判定标准,说明什么样的证据在科学意义上支持或拒绝该命题。 |
| Assay criteria | 实验层面的判定标准,将 sub-claim criteria 绑定到具体 readout,给出定量的阈值和条件。 |
可以把这个关系理解为:sub-claim criteria 是”要什么证据”,assay criteria 是”在这台仪器上,数字达到多少算拿到了那个证据”。两层说的是同一件事,只是粒度不同。
例如,对于 sub-claim:
This protein specifically binds IGF-1.
它的 sub-claim criteria 可以是:
| 判定类型 | 标准 |
|---|---|
| Support | 存在可重复的、特异性的 IGF-1 binding evidence,并且能够排除 nonspecific binding。 |
| Refutation | 在检测灵敏度范围内未观察到 IGF-1 binding,或者观察到的信号无法与 nonspecific binding 区分。 |
| Inconclusive | 有信号但不满足特异性判定条件,或重复性不足以支持任何方向的结论。 |
到了 assay 层,这些概念性的要求必须落实为定量的操作性判定。例如,如果选择 SPR binding assay,那么 assay criteria 可能写成:
| 判定类型 | 标准 |
|---|---|
| Support | 在 \(X\ \mathrm{nM}\) – \(Y\ \mathrm{nM}\) 浓度梯度范围内观察到 response \(\geq Z\ \mathrm{RU}\) 的 binding signal;拟合 binding curve 的 \(R^2 \geq W\);negative control(如 BSA 或无关蛋白)response \(< V\ \mathrm{RU}\);competition assay 中加入 \(M\)-fold excess unlabeled IGF-1 后 signal 下降 \(\geq N\%\)。 |
| Refutation | 在 \(X\ \mathrm{nM}\) – \(Y\ \mathrm{nM}\) 浓度梯度范围内 response \(< V\ \mathrm{RU}\),且仪器检测下限为 \(L\ \mathrm{RU}\)。 |
| Inconclusive | Response 介于 \(V\ \mathrm{RU}\) 和 \(Z\ \mathrm{RU}\) 之间,或三次独立重复的 \(\mathrm{CV} > P\%\)。 |
也就是说:
sub-claim criteria = 概念上的证据要求(定性)
assay criteria = 绑定具体 readout 后的操作性判定标准(定量,带阈值)
二者必须一致。Assay criteria 是 sub-claim criteria 的定量实例化:它不能偏离 sub-claim 所要求的证据方向,也不能只因为产生了某种信号就自动支持 sub-claim。它必须产生与 sub-claim statement 直接相关的证据,并通过预先设定的数值阈值来判定结果。
Assay 至少需要包含的信息
根据前面对 Assay 定义的五点拆解,一个 assay 必须包含的信息可以归为以下六大类:
1. A planned process(有计划的过程)
| 字段 | 含义 |
|---|---|
assay_type | assay 的大类类型,例如 ligand binding assay、cell-based activation assay、localization assay 等。 |
assay_template_id | 引用 assay database 中的唯一 ID。每一个 assay template 本质上是一个 DAG(有向无环图),其中 node 为 procedure,edge 为物料运输手段。具体详情见 Assay Database 章节。 |
assay_reviewed | 标志位,标记该 assay 是否已被人类专家审核。 |
2. Input(被评估的物质实体)
| 字段 | 含义 |
|---|---|
evaluant | 待测的物质实体,例如某个蛋白、细胞、复合体或样品。 |
consumables | 执行该 assay 所需的试剂或耗材,例如抗体、底物、培养基、标准品等。 |
3. Resources(物理检测所需的固定资产)
| 字段 | 含义 |
|---|---|
instruments | 所需仪器,例如 SPR 仪、流式细胞仪、酶标仪等。 |
human | 所需人力资源。这是一类比较特殊的资产:某些操作(如动物手术、临床采样)需要具备特定资质的操作人员。具体详情见物理层章节。 |
purchase | 购买试剂或耗材的过程。这是一类隐性资产需求:实验能否执行往往取决于物料是否可获得、采购周期是否可接受。 |
4. Output(产生的信息)
| 字段 | 含义 |
|---|---|
proxy | 如果无法直接检测 evaluant 的目标性质,则声明通过什么 proxy 间接获取信息。 |
readout | assay 产生的可观测数据的类型,例如 absorbance、fluorescence intensity、binding response (RU)、cell count 等。 |
5. Evidence(判定标准)
| 字段 | 含义 |
|---|---|
support_criteria | 什么样的 readout 结果支持对应 sub-claim。 |
refutation_criteria | 什么样的 readout 结果拒绝对应 sub-claim。 |
inconclusive_criteria | 什么样的情况说明该 assay 无法给出判断。 |
6. Others(其他)
| 字段 | 含义 |
|---|---|
limitations | assay 的局限性和可能的混杂因素。 |
safety_notes | 与该 assay 相关的安全、伦理和材料处理提示。 |
Assay 与 Procedure 的关系
Assay 不是 procedure。二者的区别在于粒度和设计理念。
Procedure 是一个符合工程设计理念的”高内聚、低耦合”的最小实验执行单元。一般情况下,一种 instrument 对应一种 procedure:一个 procedure 规定在某台仪器上从头到尾怎么操作——加什么、加多少、孵育多久、用什么参数上机、如何导出数据。它是自包含的,不依赖其他 procedure 的内部状态。
Assay 的 process 设计理念则类似于搭积木:将若干无法再细分的 procedure 作为最小构件,按照逻辑依赖关系组合成一个有向无环图(DAG)。在这个 DAG 中,node 是 procedure,edge 是物料或信息在 procedure 之间的传递路径。整个 DAG 加上上述六类 metadata,就构成了一个完整的 assay。
更准确地说,assay 是一个 execution-ready test specification:
- 它绑定了 evaluant、consumables、instrument class、readout 类型和 criteria;
- 它通过引用 assay template 确定了 procedure 的组合方式和执行顺序;
- 它说明什么样的仪器输出会被解释为 support、refutation 或 inconclusive;
- 但它不规定每一步操作的体积、时间、温度、plate layout、仪器 method file 和 operator action sequence。
这些逐步执行细节属于 procedure 层,由 DAG 中的各个 node 分别承载。
从 Sub-claim 到 Assay 的匹配过程
从 sub-claim 到 assay 的匹配不是一条线性流水线,而是一个包含分支、淘汰和人工确认的多轮交互过程。下面用一张序列图展示整体流程,再逐步展开。
sequenceDiagram
autonumber
participant S as 📋 Sub-claim
(喝咖啡)
participant R as 📦 Resource
(资源)
participant A as 🧪 Assay
(实验流程)
participant D as ⚙️ Physical Layer
(物理层)
Note over S: 🧠 think:分解子目标
①速溶 ②滴滤 ③购买
%% ===== 子目标①: 速溶 =====
rect rgb(255, 235, 235)
Note over S: 处理子目标 ① 速溶
S ->>+ R: 查看资源:有没有相关资源(速溶咖啡粉,杯子,水)?
R ->> R: retrieve / think(内部检索)
R -->>- S: 没有速溶咖啡粉,有杯子,白开水
Note over S: ❌ drop — 放弃①速溶
end
rect rgb(255, 248, 230)
Note over S: 处理子目标 ② 滴滤
S ->>+ R: 有没有相关资源(咖啡豆粉或咖啡豆+磨豆机,滤纸,杯子,热水)?
R ->> R: retrieve / think(内部检索)
R -->>- S: ✅ 有咖啡豆,磨豆机,滤纸,杯子,热水
S ->>+ A: 怎么用?
A ->> A: retrieval / think → 没有现成 assay
Note over A: 追问 → rank assays
Note over A: 接热水
摩卡壶萃取咖啡(包含磨咖啡豆的procedure)
化学实验重力过滤(包含使用滤纸的procedure)
...
Note over A: think
通过组合形成新的 assay
Note over A: 👤 请求人类反馈
A -->> A: 人类确认 → 通过 ✅
A -->>- S: 返回新组合 assay
Note over S: 📎 bind metadata
end
rect rgb(232, 255, 232)
Note over S: 处理子目标 ③ 购买
S ->>+ R: 有没有相关资源(咖啡店)?
R ->> R: retrieve / think(内部检索)
R -->>- S: ✅ 有咖啡店
S ->>+ A: 怎么用?
A ->> A: think / retrieval(内部检索)
A -->>- S: ✅ 有现成 assay
Note over S: 📎 bind metadata
end
rect rgb(245, 240, 255)
Note over S: 📋 bind metadata + bind assay
汇总:①✗ ②✓ ③✓
含:比较 成本 / 时间 / 风味
Note over S: think
综合分析选项并给出理由
Note over S: 请求人类专家最后确认
S ->>+ D: 🚀 执行
Note over D: 物理层执行任务
D -->>- S: 完成
end
从这个例子中可以提炼出一般性的匹配流程:
sub-claim
-> think: 分解可能的实现路径(sub-goals)
-> for each sub-goal:
-> 查询 Resource:是否具备必要资源?
-> if 资源不足 → drop 该路径
-> if 资源具备 → 查询 Assay Database:有没有现成 assay?
-> if 有 → 直接绑定
-> if 没有 → 检索相关 assay → rank → 组合/改写 → 请求人类确认
-> bind metadata
-> 汇总所有可行路径,比较并排序
-> 请求人类专家最终确认
-> 下发至物理层执行
1. Think:分解可能的实现路径
拿到一个 sub-claim 后,第一步不是直接去检索 assay,而是先思考:要验证这个 sub-claim,有哪些可能的实验路径?
例如,对于 sub-claim:
This protein specifically binds IGF-1.
可以分解出多条可能的实现路径:
- ① 用纯化蛋白在 SPR 上做 binding(in vitro, purified protein)
- ② 用表达该蛋白的细胞做 ligand binding(cell-surface binding)
- ③ 用 pull-down 或 co-IP 做间接结合检测(interaction assay)
- ④ 委托外部 CRO 执行 binding assay(外包)
这些路径之间并不互斥,但它们对资源、仪器和实验体系的要求完全不同。把它们列出来的目的是:不要过早锁死在一条路径上,而是先展开可能性,再用资源约束做筛选。
2. 查询 Resource:当前是否具备必要资源?
对于每一条实现路径,首先检查:执行这条路径所需的资源是否可获得?
这里的”资源”包括前面 Assay 定义中的 input 和 resources 两类:
- evaluant 是否可获得?(例如:纯化的候选蛋白是否已经拿到?)
- consumables 是否可获得?(例如:recombinant IGF-1 是否有货?sensor chip 是否有库存?)
- instruments 是否可用?(例如:实验室是否有 SPR 仪?是否能预约到机时?)
- human 是否满足?(例如:是否有人会操作 SPR?是否需要特定资质?)
- purchase 是否可行?(例如:如果缺某种试剂,采购周期是否可接受?)
如果某条路径的关键资源缺失且无法在合理时间内补齐,则直接 drop 该路径,不进入后续 assay 检索。
例如:
| 路径 | 资源检查结果 | 决策 |
|---|---|---|
| ① SPR binding | 没有 SPR 仪,也无法借用 | ❌ drop |
| ② Cell-surface binding | 有表达该蛋白的稳转细胞株,有流式细胞仪 | ✅ 继续 |
| ③ Co-IP / pull-down | 有抗体、有蛋白、有试剂 | ✅ 继续 |
| ④ 外包 CRO | 有预算、有合作 CRO | ✅ 继续 |
资源检查是一个 gate:它在进入 assay 检索之前就淘汰掉不可执行的路径,避免后续产生无法落地的 assay specification。
3. 查询 Assay Database:是否有现成 assay?
对于通过资源检查的路径,接下来查询 assay database:针对这条路径,是否有现成的、可直接使用的 assay template?
查询时需要用到的信息包括:sub-claim statement、实现路径描述、evaluant 类型、target relation(例如 binding)、所用 instrument class、organism 或 cell type 等。
查询结果有两种情况:
情况 A:找到现成 assay
如果 assay database 中有一个已有 template 在 evaluant、target relation、readout、context 和 controls 上都与当前路径对齐,那么可以直接选中这个 assay 并绑定到当前 sub-claim。
例如:路径④”外包 CRO”可能对应一个已有 assay template——”CRO binding assay service order”,其中 evaluant、readout、criteria 都已定义好,只需要填入具体样品信息即可。
此时直接进入 bind metadata 步骤。
情况 B:没有现成 assay
如果没有完全匹配的 assay template,则需要进入检索、排序和组合流程。
4. 检索相关 assay → Rank → 组合或改写
当没有现成 assay 时,不应该凭空创造实验方案。正确的做法是:
4.1 检索相关 assay
在 assay database 中检索与当前路径部分相关的 assay templates。检索不要求完全匹配,而是寻找在某些维度上可复用的模板。
例如,对于路径②”cell-surface binding”,可能检索到:
- Assay T-041:flow cytometry cell-surface receptor binding assay(检测 EGF binding,不是 IGF-1)
- Assay T-089:radioligand binding assay on membrane fractions(检测 IGF-1 binding,但用膜组分不是完整细胞)
- Assay T-112:fluorescence-based ligand binding on live cells(检测 insulin binding on adipocytes)
这些 assay 都不完全匹配当前需求,但它们各自贡献了可复用的组件:某个提供了 cell-surface binding 的实验逻辑,某个提供了 IGF-1 相关的 control 设计,某个提供了 live cell fluorescence readout 的 procedure。
4.2 Rank
对检索到的候选 assay 进行排序。排序时重点考虑:
- evaluant 是否匹配(对象是否一致)
- target relation 是否匹配(检测的关系是否一致,例如 binding vs. activation)
- readout 逻辑是否可复用
- context 是否兼容(in vitro vs. cell-based vs. in vivo)
- controls 是否充分
- assay template 来源是否可靠(文献、数据库、SOP、经审核模板)
- 所需资源是否与已确认的可用资源一致
4.3 组合或改写,形成新 assay
回顾前面对 assay 的定义:assay 的 process 是一个 DAG,其中 node 为 procedure,edge 为物料运输。既然 assay 本身就是由 procedure 搭建而成的,那么当没有现成 assay 时,可以从排序靠前的候选 assay 中抽取可复用的 procedure nodes,重新组合成一个新的 DAG。
这个过程类似搭积木:
- 从 Assay T-041 中取出”flow cytometry staining and acquisition” procedure
- 从 Assay T-112 中取出”fluorescence-labeled ligand preparation” procedure
- 将 ligand 替换为 IGF-1,将 cell type 替换为表达候选蛋白的细胞
- 补充 competition control procedure(加入 unlabeled IGF-1 竞争)
- 将这些 procedure 按逻辑依赖关系连成 DAG,形成新的 assay
新生成的 assay 必须记录其来源:
assay_id: A_new_002
parent_assay_ids:
- T-041
- T-112
adaptation_required: true
assay_reviewed: false
adaptation_summary:
- replaced ligand from EGF to fluorescence-labeled IGF-1
- replaced target cells to candidate-protein-expressing cells
- added competition control with unlabeled IGF-1
- retained flow cytometry acquisition and gating procedure from T-041
4.4 请求人类确认
任何通过组合或改写生成的新 assay,在绑定到 sub-claim 之前必须请求人类专家确认。新 assay 的 assay_reviewed 标志位在人类确认之前始终为 false。
人类专家需要确认的内容包括:
- 新 assay 的 DAG 结构是否合理(procedure 之间的依赖是否正确)
- evaluant、ligand、controls 的选择是否合适
- readout 是否足以支持或拒绝 sub-claim
- criteria 定义是否清晰、可执行
- 是否存在遗漏的混杂因素或 controls
只有在人类确认通过后,assay_reviewed 才可以被置为 true,该 assay 才能进入后续流程。
5. Bind metadata
无论是直接选中现成 assay(情况 A),还是通过组合生成新 assay(情况 B),选定后都需要将 assay 的 metadata 完整绑定到当前 sub-claim。
绑定的信息对应前面定义的六大类:
# 1. A planned process
assay_type: cell-based ligand binding assay
assay_template_id: A_new_002
assay_reviewed: true
# 2. Input
evaluant: HEK293 cells stably expressing candidate protein X
consumables:
- fluorescence-labeled recombinant IGF-1
- unlabeled recombinant IGF-1 (competition control)
- FACS buffer
- viability dye
# 3. Resources
instruments: flow cytometer (e.g. BD LSRFortessa)
human: flow cytometry operator
purchase: fluorescence-labeled IGF-1 (vendor, catalog, lead time)
# 4. Output
proxy: fluorescence intensity on cell surface as proxy for ligand binding
readout: median fluorescence intensity (MFI) of labeled IGF-1 on gated live cells
# 5. Evidence
support_criteria: >
MFI of candidate-protein-expressing cells significantly higher than
negative-control cells; signal reduced by ≥50% in competition condition.
refutation_criteria: >
No significant difference in MFI between candidate and negative-control cells.
inconclusive_criteria: >
High background, low viability, or inconsistent replicates preventing
reliable comparison.
# 6. Others
limitations: >
Cannot distinguish direct binding from indirect association via
co-expressed adaptor proteins.
safety_notes: handle fluorescent dyes according to MSDS; standard BSL-1 cell culture.
其中最关键的是:criteria 必须绑定到具体 readouts,而不能只写成泛泛的”结果显著”或”有阳性信号”。只有 criteria 足够具体,后续 assay result 才能被稳定地转换成 sub-claim status(support / refutation / inconclusive)。
6. 汇总、比较与最终确认
当所有通过资源检查的路径都完成了 assay 绑定后,需要汇总所有可行方案进行比较。
例如:
| 路径 | 状态 | 成本 | 时间 | 证据强度 |
|---|---|---|---|---|
| ① SPR binding | ❌ dropped(无仪器) | — | — | — |
| ② Cell-surface binding (flow) | ✅ assay bound | 中 | 1–2 周 | 中(间接,proxy) |
| ③ Co-IP / pull-down | ✅ assay bound | 低 | 1 周 | 中(间接,但互补) |
| ④ CRO 外包 | ✅ assay bound | 高 | 4–6 周 | 高(SPR,直接) |
比较维度可以包括:成本、时间、证据强度、风险、是否需要额外采购、是否互补等。
最终由人类专家综合判断选择执行哪些路径(可以选多条互补路径),确认后下发至物理层生成 procedure 并执行。
流程设计的思路
需要强调的是,这个流程与简单的”sub-claim → 检索 assay → 执行”有几个关键区别:
第一,资源检查前置于 assay 检索。不是先找到 assay 再看能不能做,而是先确认资源可用性,再去找或组合 assay。这避免了生成大量无法落地的 assay specification。
第二,允许多条路径并行展开。一个 sub-claim 可能有多种验证方式,它们不是互斥的。系统应该把所有可行路径都展开,最后由人类根据成本、时间、证据强度等因素选择。
第三,assay 的生成是”基于已有模板的受控组合”,而不是凭空创造。当没有现成 assay 时,系统从 assay database 中检索相关 templates,抽取可复用的 procedure nodes,重新组装成新的 DAG。这保证了新 assay 的每个组成部分都有据可循。
第四,人类确认嵌入在流程中间,而不是只在最后。特别是对于组合生成的新 assay,必须在绑定之前就经过人类审核,而不是等到所有 assay 都定完之后再统一审批。
Iteration
由于中间层的下一步就是物理层,因此这里必须进行严格的内容检查。
如果中间层中任何一个环节出现问题,例如 sub-claim 拆解不完整、Boolean 逻辑不准确、assay 与 sub-claim 不匹配、readout 不能支持判定、缺少 controls 或 criteria 不清晰,都应该进入 iteration,而不是直接进入物理层执行。
中间层的检查可以分成以下几类。
1. Claim-to-Sub-claim 逻辑检查
需要检查的问题包括:
| 检查项 | 说明 |
|---|---|
| sub-claims 是否覆盖了 claim 的关键含义? | 如果 claim 中包含 binding 和 signaling,但 sub-claims 只覆盖 binding,那么拆解不完整。 |
| sub-claims 是否过度扩展了 claim? | 不应该加入原始 claim 没有暗示的新命题。 |
| sub-claims 是否粒度合适? | 太粗会难以验证,太细会导致组合逻辑复杂。 |
| support/refutation 逻辑是否合理? | 需要明确哪些 sub-claims 支持时可以支持 claim,哪些 sub-claims 被拒绝时可以拒绝 claim。 |
| 是否允许 inconclusive 状态? | 不能把所有 negative 或 failed assay 都当成 refutation。 |
例如,对于弱版本 IGF receptor claim:
support(C0) = supported(S1) OR supported(S2)
refute(C0) = refuted(S1) AND refuted(S2)
inconclusive(C0) = NOT support(C0) AND NOT refute(C0)
这个逻辑是合理的,因为只要支持 IGF-1 或 IGF-2 binding 中任意一个,就可以支持“该蛋白是某种 IGF ligand 的 receptor”这个较弱版本 claim。
但是,对于强版本 claim,就必须加入 activation 或 signaling:
support(C0_strong) = (supported(S1) OR supported(S2)) AND supported(S3)
否则,系统可能会把一个只能结合 IGF ligand、但没有 receptor activation 功能的蛋白错误地判断为 functional receptor。
2. Sub-claim-to-Assay 对齐检查
每一个 sub-claim 都需要至少有一个对应 assay。
需要检查的问题包括:
| 检查项 | 说明 |
|---|---|
| 每个 sub-claim 是否都有对应 assay? | 如果没有 assay,就无法进入物理层。 |
| assay 是否真的测试了 sub-claim? | 不能用不相关 readout 间接替代。 |
| assay 的 proxy 是否合理? | 如果 proxy 与目标性质关系太远,结果解释会不可靠。 |
| assay 是否有 positive control 和 negative control? | 没有 controls 的结果很难解释。 |
| assay 是否有明确的 support/refutation/inconclusive criteria? | 如果没有 criteria,实验结果无法自动回填到 sub-claim 状态。 |
例如:
| sub-claim | 错误 assay 匹配 | 问题 |
|---|---|---|
| This protein specifically binds IGF-1. | 只检测该蛋白的表达量。 | 表达量不能说明它是否结合 IGF-1。 |
| This protein activates downstream signaling after IGF stimulation. | 只做 in vitro ligand binding。 | ligand binding 不能证明 downstream signaling。 |
| This protein localizes to mitochondria. | 只做 sequence similarity search。 | 序列相似性可以作为预测证据,但不是物理检查意义上的 localization assay。 |
3. Assay 可执行性检查
Assay 需要足够具体,才能交给物理层继续转换为 procedure。
需要检查的问题包括:
| 检查项 | 说明 |
|---|---|
| readouts 是否明确? | 例如 binding response、fluorescence intensity、phosphorylation level、cell count 等。 |
| required instruments 是否明确? | 例如 SPR、plate reader、flow cytometer、microscope、LC-MS 等。 |
| required consumables 是否明确? | 例如 ligand、antibody、substrate、cell line、buffer、sensor chip 等。 |
| controls 是否明确? | 包括 positive control、negative control、blank、vehicle control 等。 |
| replicates 是否明确? | 至少需要说明技术重复和生物重复的要求由 assay template 或实验上下文决定。 |
| criteria 是否绑定 readouts? | support/refutation 不能只写“结果显著”,而要说明针对哪个 readout。 |
| limitations 是否记录? | 例如 proxy 不直接、背景高、内源性通路干扰、样本质量依赖等。 |
4. 信源检查
Assay 选择需要有可追溯来源。
需要检查的问题包括:
| 检查项 | 说明 |
|---|---|
| assay 是否来自已有知识库、文献、数据库或 SOP? | 避免凭空生成 assay。 |
| 是否记录了 source 或 template? | 后续可以追踪 assay 的来源。 |
| 是否说明了 adaptation? | 如果对已有 assay 做了修改,需要记录修改内容和原因。 |
| source 是否与当前 sub-claim 匹配? | 不能引用一个看似相关但实际 evaluant、readout 或 context 不匹配的 assay。 |
可以为每个 assay 记录:
source_or_template:
type: literature | database | internal_SOP | expert_defined_template
citation: ...
matched_components:
- evaluant
- analyte_or_ligand
- readout
- controls
adaptations:
- replaced ligand with IGF-1
- changed readout from endpoint signal to dose-response curve
- added competition control
justification: >
This assay template directly measures ligand-protein binding,
which is aligned with the sub-claim that the candidate protein
specifically binds IGF-1.
5. 结果模拟检查
在真正进入物理层之前,最好先做一次“结果模拟”。
也就是说,假设每个 assay 最后返回不同结果,检查系统是否能够根据这些结果自动判断最终 claim 的状态。
例如,对于弱版本 claim:
C0: This protein functions as a receptor for IGFs.
S1: This protein specifically binds IGF-1.
S2: This protein specifically binds IGF-2.
support(C0) = supported(S1) OR supported(S2)
refute(C0) = refuted(S1) AND refuted(S2)
inconclusive(C0) = NOT support(C0) AND NOT refute(C0)
可以模拟如下结果:
| A1 result | S1 status | A2 result | S2 status | final C0 status |
|---|---|---|---|---|
| positive binding | supported | negative binding | refuted | supported |
| negative binding | refuted | positive binding | supported | supported |
| negative binding | refuted | negative binding | refuted | refuted |
| assay failed | inconclusive | negative binding | refuted | inconclusive |
| assay failed | inconclusive | assay failed | inconclusive | inconclusive |
| positive binding | supported | assay failed | inconclusive | supported |
如果这个模拟表无法填写,或者填写后无法得到稳定判断,就说明中间层设计还不完整,需要回到 sub-claim 或 assay 层重新修改。
中间层的最终输出
一个完整的中间层输出,至少应该包含以下几个部分:
- Sub-claim table
- 每个 sub-claim 的 ID、statement、scope、support criteria、refutation criteria、inconclusive criteria。
- Claim decision rules
- 如何由 sub-claims 的状态组合得到最终 claim 的状态。
- 最好使用 Boolean logic 或更明确的 decision rules 表示。
- Assay table
- 每个 sub-claim 对应哪些 assays。
- 每个 assay 的 readouts、controls、replicates、criteria、resources 和 limitations。
- Assay-source mapping
- 每个 assay 来自哪个知识库、文献、SOP 或模板。
- 如果做了 adaptation,需要记录 adaptation 的内容和理由。
- Alignment report
- 检查每个 assay 是否真的能支持或拒绝对应 sub-claim。
- Simulation report
- 模拟不同 assay 结果是否可以推出最终 claim 的状态。
- Iteration flags
- 标记哪些地方需要人工审查、补充信息或重新设计。
可以用下面这个结构概括中间层的工作流:
Claim
-> decompose into Sub-claims
-> define decision rules
-> retrieve candidate Assays
-> rank and adapt Assays
-> define readouts and criteria
-> validate Sub-claim-Assay alignment
-> simulate possible outcomes
-> output to physical layer
因此,中间层的核心任务可以总结为:
将概念层中的 claim 转换成一组可实验判定的 sub-claims,并为每个 sub-claim 匹配能够产生证据的 assay,同时定义清楚从 assay result 到 sub-claim status,再到 final claim status 的判断规则。
只有完成这一步之后,物理层才能真正开始生成 procedure、分配仪器、安排实验人员或调用自动化设备。